Catch more fraud. Raise fewer alarms.
Autographer mines your own history for the fraud patterns your models miss, then hands your team evidence-scored control candidates with estimated capture, alert load, and review context.
amount > 50000 ∧ channel = AGENT
beneficiary_is_new ∧ count_1h > 3
geo_location = high-risk bucket
amount > 50000 (sup 42 · prec 0.90) was mined as strong evidence but dropped from the generated model. Fix before testing.
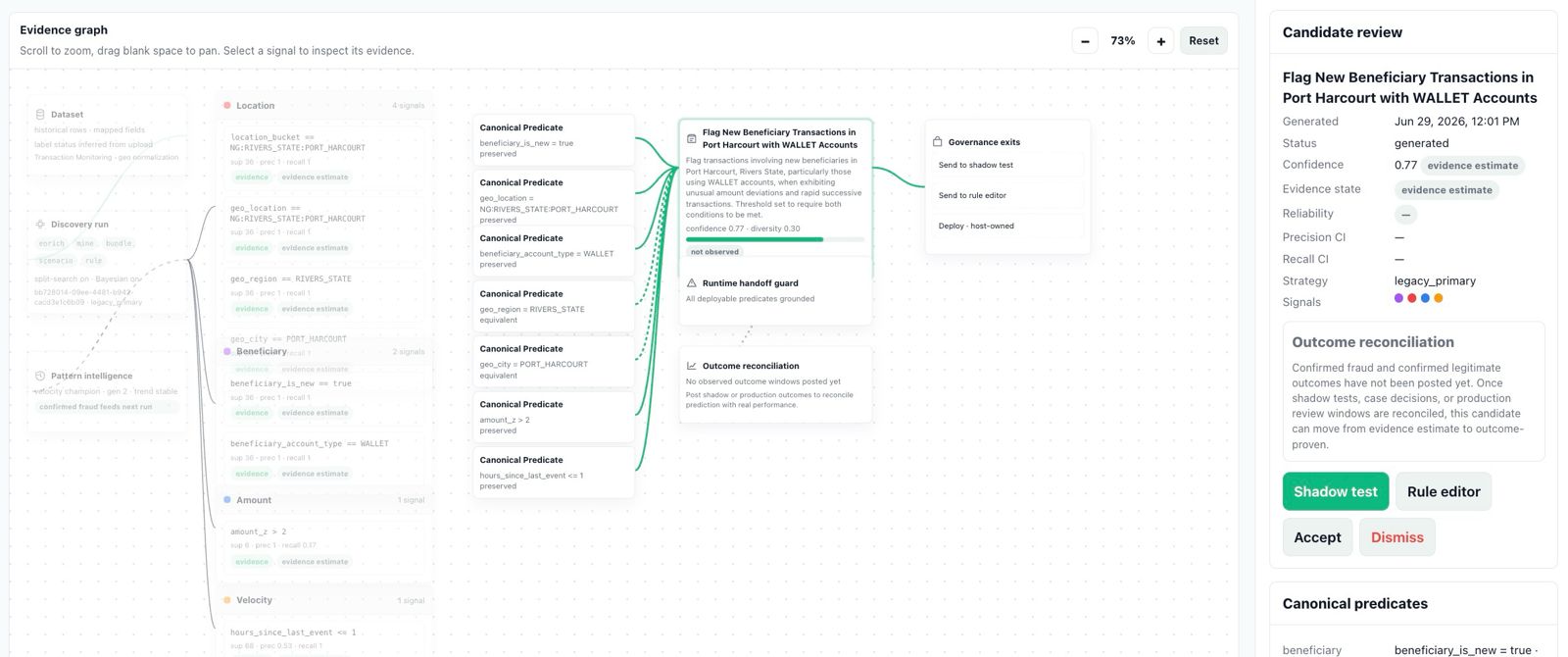
Not a mockup: the Evidence Canvas as analysts see it, candidate review panel and all.
The pattern hunting your analysts do by hand, across amounts, channels, beneficiaries, velocity, and geography, runs in minutes, with the statistics attached.
Every candidate estimates alert load next to expected capture. Your team can test the trade-off before it hits the queue.
When losses spike in a new attack vector, run discovery on the fresh data and ship a reviewed control the same week.
Every control traces to evidence in your own data: support, reliability metrics, lineage, approvals, and labeled-outcome metrics where available.
Generic AI can suggest fraud patterns. It can't defend them.
Pattern discovery today sits between two bad options: manual analysis that takes weeks, and generic AI that produces answers no reviewer can verify.
Fast, but unaccountable
- Suggestions sound plausible, but carry no evidence you can verify.
- No support, reliability, or outcome context. Nothing useful to show a model-risk reviewer.
- The output isn't deployable logic; it still has to be rebuilt by hand.
- Same prompt, different answer every time. Nothing is reproducible.
- Sensitive transaction data has to leave your environment.
Evidence-graded discovery, in your environment
- Every candidate traces to mined patterns with support and reliability metrics; labeled data adds precision and recall.
- Estimated alert load is shown before shadow testing: expected capture and review cost, side by side.
- Output is review-ready control logic for shadow testing and governed deployment.
- Deterministic by design: same data, same patterns, every run.
- Runs where your data lives. Raw source data is not retained by default after the run.
Discover. Review. Ship.
Autographer drafts; your team decides. Human-in-the-loop by design.
Discover
Upload a file or connect a dataset. With labels, it learns from outcomes; without them, it hunts for suspicious structure. Raw source data is not retained by default.
Review the evidence
Open any candidate in the Evidence Canvas: source patterns, support, reliability, labeled-outcome metrics where available, and generation warnings. Approve, adjust, or reject.
Ship
Send approved candidates to shadow testing in Loci's decision engine (MADIE) or your existing workflow. Deployment stays governed and logged.
See the capture and the estimated alert load before testing.
Every candidate is ranked by estimated fraud capture, alert load, and evidence quality, and traces back to the patterns in your data. Production deployment remains governed and reviewable.
| Control candidate | Fraud capture | False-positive rate | Evidence |
|---|---|---|---|
| Block cards with prior chargeback history | 87% | 0% | see evidence → |
| Flag high-risk email domains | 63% | 2.1% | see evidence → |
| Review orders > $10k from high-risk regions | 41% | 4.3% | see evidence → |
It checks its own work, then keeps checking.
Generated logic is proofread against the mined evidence before review, and reconciled against real-world outcomes after deployment.
An automatic proofreader compares every generated model against its evidence, and flags dropped clues, dead clauses, and weak support.
amount > 50000 dropped from model
▲ DEAD_CLAUSE · condition never matches
● all other predicates grounded
Predicted performance is tracked against observed reality, precision, alert rate, and drift, so a control that decays gets caught, not trusted.
alert rate · pred 3.5% vs obs 3.1%
● tracking · mature after 3 windows
▲ drift watch if deltas widen
Patterns that persist across repeated runs become champions. Autographer tracks how their reliability metrics, outcome-backed precision where available, and thresholds evolve over generations.
precision 0.71 → 0.79 → 0.86 → 0.90
threshold drift 30k → 42k → 50k → 54k
channel = AGENT · gen 3 · stable
Walk into model-risk review with the evidence ready.
Black-box vendor findings, fair-lending scrutiny, audit requests, everything a reviewer will ask for is generated as a by-product of how Autographer works, not reconstructed afterwards.
Separate search and validation windows show how a candidate behaves out of sample, not just on the data that suggested it.
Every candidate carries its alert load, not just its fraud capture, so alert fatigue is a decision, never a surprise.
Deterministic discovery: the same data produces the same patterns, every run. No agent improvisation in the loop.
Run, source patterns, evidence state, and approvals recorded for every control, defensible end to end.
Prove value on one surface. Extend to the next.
Domain profiles adapt the same discovery engine to new fraud surfaces, new features and vocabulary, not new projects.
Money movement, beneficiary, velocity, and location signals across payments and transfers.
Call, verification, reset, and account-compromise patterns from contact-center event streams.
Repeatable abuse patterns surfaced from profile-specific features across claims and refunds.
Bring one dataset. See the controls it finds.
In 30 minutes, watch patterns in your own data become review-ready control candidates, evidence and all. Discovery only; raw source data is not retained by default after the run.